Natural Language Processing Projects
A collection of NLP pipelines focused on text classification, semantic similarity, and generative tasks.
Includes reusable preprocessing and embedding workflows for search, summarization, and classification-style use cases.
Project Details
Technologies
The Problem
Processing unstructured text data requires multi-stage cleaning and embedding strategies to extract meaningful signal from noise.
The Solution
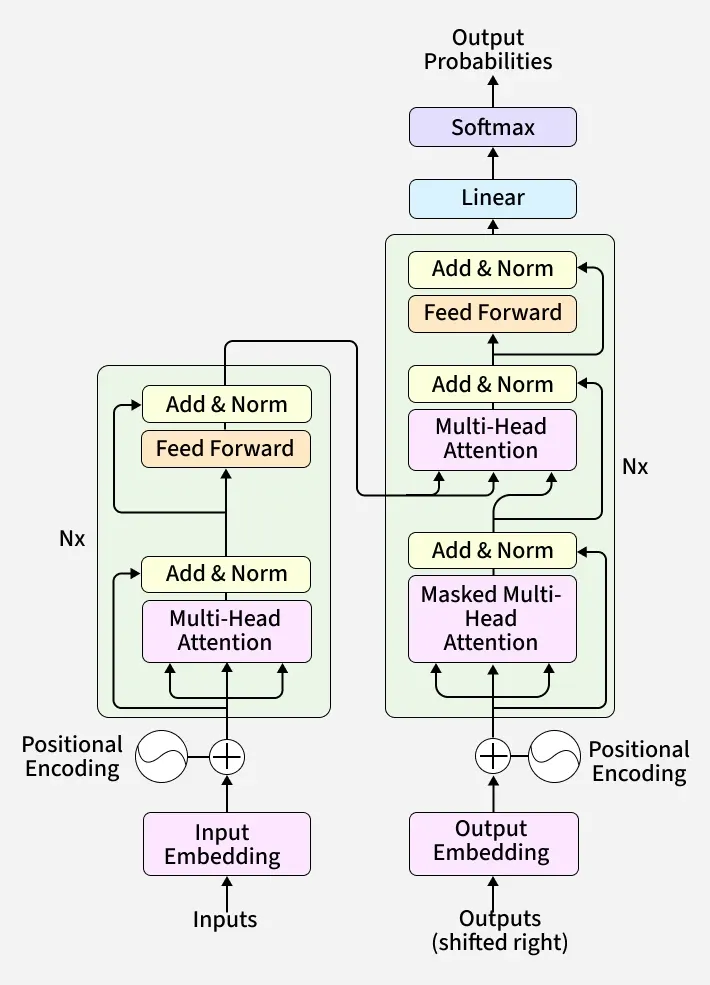
Developed custom pipelines using SpaCy and HuggingFace Transformers. Features include sentiment analysis engines, semantic search based on cosine similarity, and text summarization modules.
Architecture & Implementation
- NLP Libraries: SpaCy, NLTK, and Transformers.
- Embeddings: Use of BERT and Word2Vec for vector representation.
- Deployment: Lightweight API endpoints for real-time text processing.
Results & Impact
Created a reusable NLP toolkit that has been applied to various projects for automating document classification and enhancing search capabilities.